|
|
|
Smart Search (e-shop)
|
|
|
Úvod a popis architektury
Funkce Smart Search slouží k rychlému a efektivnímu vyhledávání v rámci e-shopu. Nabízí možnost fulltextového vyhledávání včetně skloňování, použití synonym, detekce překlepů a řazení výsledků dle relevance.
Díky Smart Search je možné vyhledávat také v názvech a popisech kategorií zboží, značek produktů nebo názvech a obsahu blogových článků. Vyhodnocení lze provádět pomocí integrace se službou Google Analytics.
Na rozdíl od ostatních možností vyhledávání se v tomto případě využívá místo SQL dotazů specializovaný nástroj Elasticsearch určený primárně pro vyhledávání a analýzu dat.
Samotný Elasticsearch je multiplatformní open source produkt, který musí být nainstalován samostatně a pro provoz Smart Search je nutnou součástí. K2 i K2 e-shop implementují komunikační rozhraní, kterým můžou s Elasticsearch komunikovat.
Pro potřeby K2 e-shopu je doporučeno Elasticsearch nasadit na samostatný server na platformě linux. Možné, ale pro produkční provoz nepodporované nasazení, je také instalace Elasticsearch na platformě MS Windows.
Pro celkovou funkčnost je nutné zajistit, aby mohla s tímto serverem probíhat komunikace na TCP portu 9200 (výchozí nastavení) jak z vnitřní sítě ze služby K2 Aplikační server, případně terminálového serveru/klientských stanic, na kterých uživatelé provozují K2, tak ze strany K2 e-shopu (tedy typicky serveru umístěného v DMZ).
|
|
|
Architektura K2 (varianta s Elasticsearch na OS Linux)
Nasazení na samostatný server na platformě Linux umístěný v DMZ.
Minimální požadavky: 8GB RAM, 2 jádra CPU, 30GB disk.
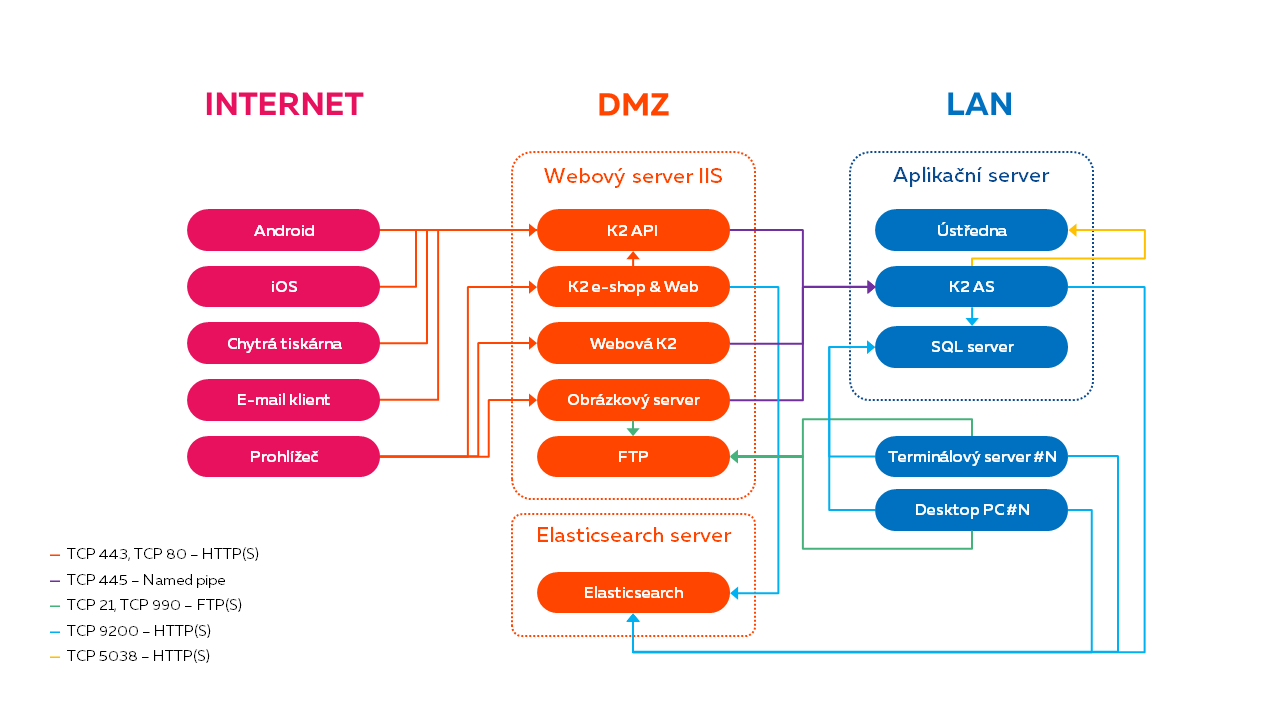
Obr. Doporučené produkční nasazení (Linux)
|
|
|
Architektura K2 (varianta s Elasticsearch na OS Windows)
Tato varianta je typická pro testovací provoz e-shopu.
Server AS musí mít kromě požadavků ostatních služeb navíc k dispozici alespoň 2GB RAM a dostupnou kapacitu CPU pro provoz Elasticsearch.
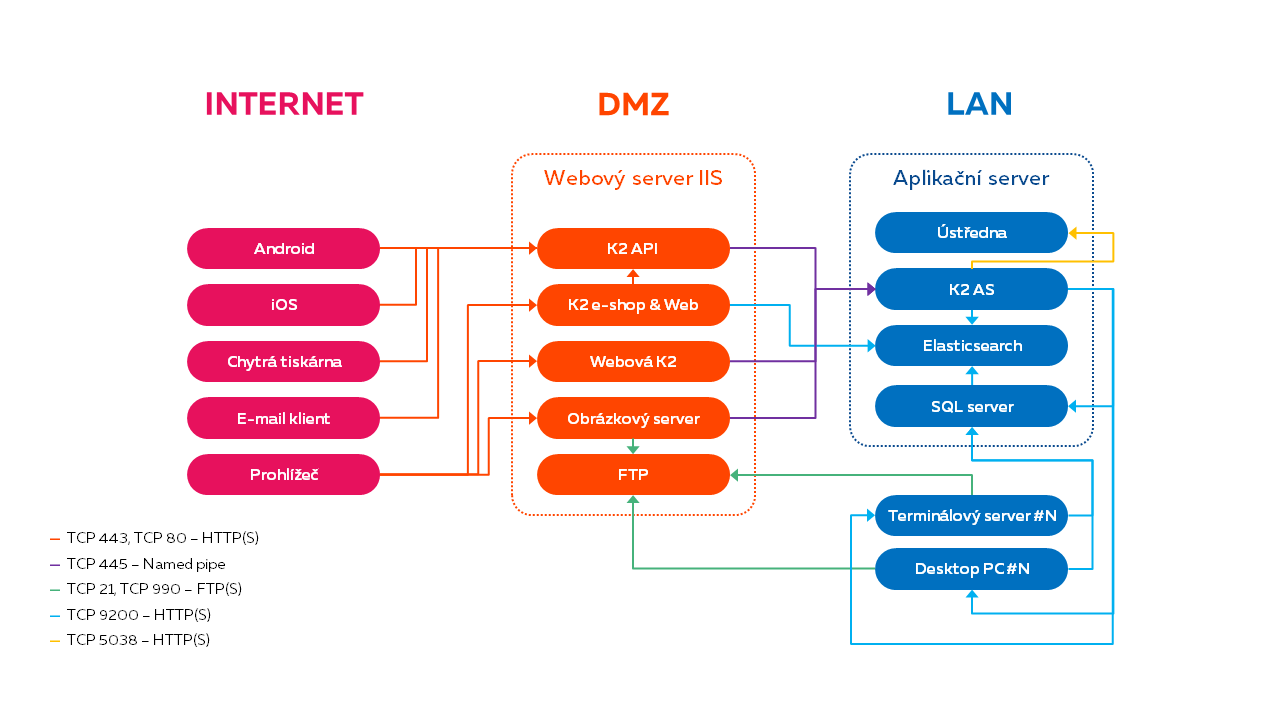
Obr. Nasazení pro testování (Windows)
|
|
|
Instalace Elasticsearch (Linux)
Různé možnosti základní instalace na platformě Linux jsou podrobně popsány na stránkách výrobce Elasticsearch:
https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
Mimo základní instalaci je potřeba instalovat tyto doplňky:
- ICU Analysis plugin: https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-icu.html
- Slovníky pro použité jazyky – viz postup v kapitole „Instalace slovníků pro Elasticsearch„.
|
|
|
Instalace Elasticsearch (Windows)
Pro provoz na platformě Windows je nejjednodušší stažení ms instalátoru služby Elasticsearch z oficiálních stránek: https://www.elastic.co/guide/en/elasticsearch/reference/current/windows.html
Na této stránce je také podrobný návod pro instalaci. Dále jsou uvedeny jen nejdůležitější a doporučená nastavení. Nastavení, které je zde popsáno je podle defaultního nastavení podle msi instalátoru služby Elasticsearch.
Záložka Service
Na záložce Locations Service Configuration Plugins X-Pack instalovat jako službu Use Local System account a použít automatické spuštění.
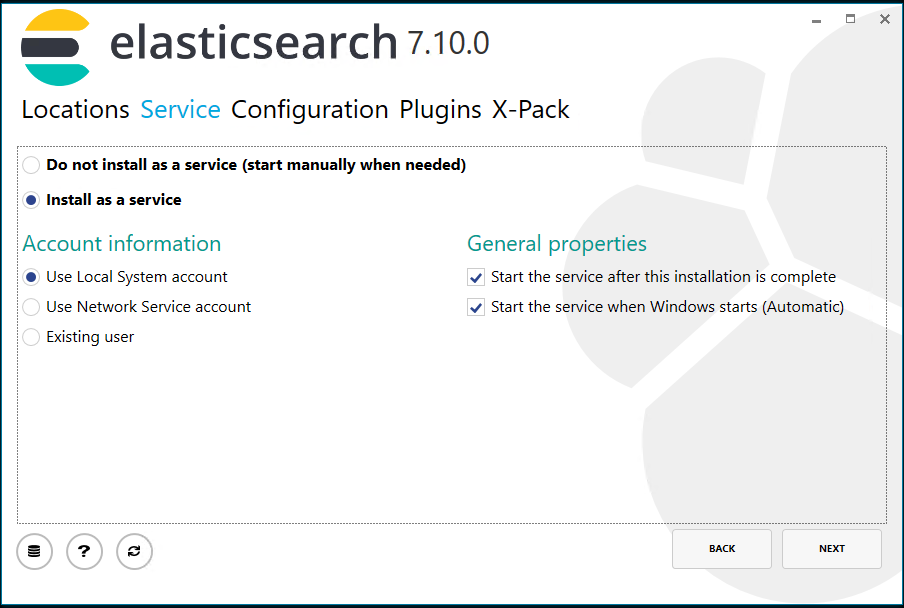
Obr. Záložka Locations Service Configuration Plugins X-Pack
Záložka Configuration
Pro základní instalaci Elasticsearch ponechat ve výchozím stavu.
Změnit Cluster name, např. na es-k2web a do Network host zapsat 0.0.0.0. Tím dojde k povolení přístupu i z jiných serverů/stanic.
Zatrhnout pole This is the first master in new cluster.
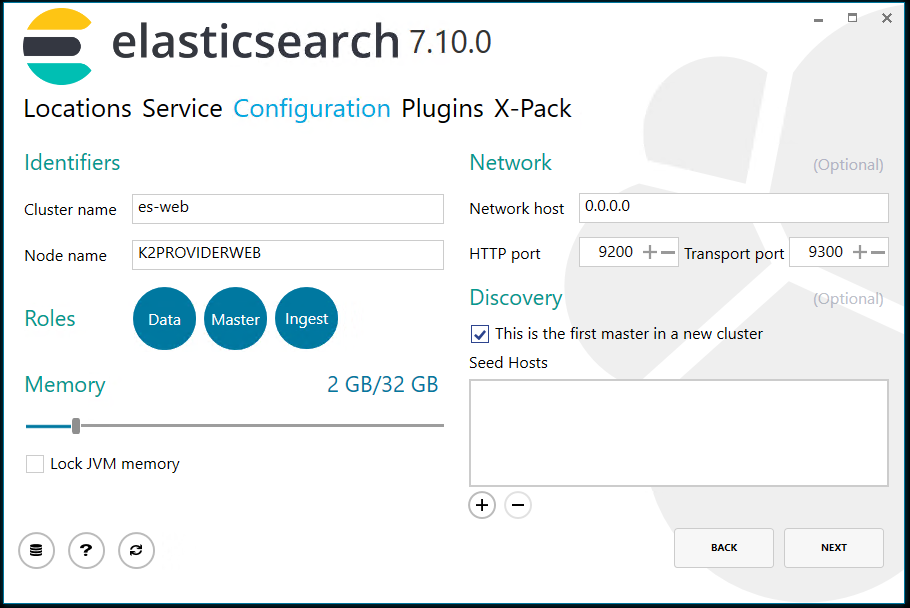
Obr. Záložka Configuration
Záložka Plugins
Zatrhnout pole ICU Analysis.
Pokud proběhla instalace úspěšně, objeví se ve správě služeb služba s názvem Elasticsearch.
|
|
|
Instalace slovníků pro Elasticsearch
Aby mohla správně fungovat analýza textu a slov pro různé jazyky, je potřeba do Elasticsearch doplnit odpovídající slovníky projektu Hunspell.
Slovníky pro jednotlivé jazyky lze stáhnout například z této stránky: http://download.services.openoffice.org/contrib/dictionaries/
Pro češtinu např. stáhneme soubor cs_CZ.zip. Pro angličtinu en_GB.zip nebo en_US.zip (podle preference britské nebo americké angličtiny).
Stažený ZIP soubor rozbalíme do adresáře s konfiguračními soubory Elasticsearch, tj. adresář zadaný v prvním kroku instalace (zde podle defaultního nastavení Msi instalátoru). Ve výchozím stavu je to C:\ProgramData\Elastic\Elasticsearch\config. Případně /etc/elasticsearch na platformě linux nebo podadresář config v místě rozbalení archivu s Elasticsearch.V tomto adresáři vytvoříme podadresář hunspell a v něm podadresář dle označení jazyka (např. „cs_CZ“). Do vytvořeného adresáře rozbalíme obsah staženého archivu (minimálně soubory s příponou .aff a .dic).
Dále vytvoříme soubor settings.yml, který bude obsahovat tento řádek:
strict_affix_parsing: true
Takto postupujeme pro všechny jazyky, v nichž potřebujeme na e-shopu vyhledávat.
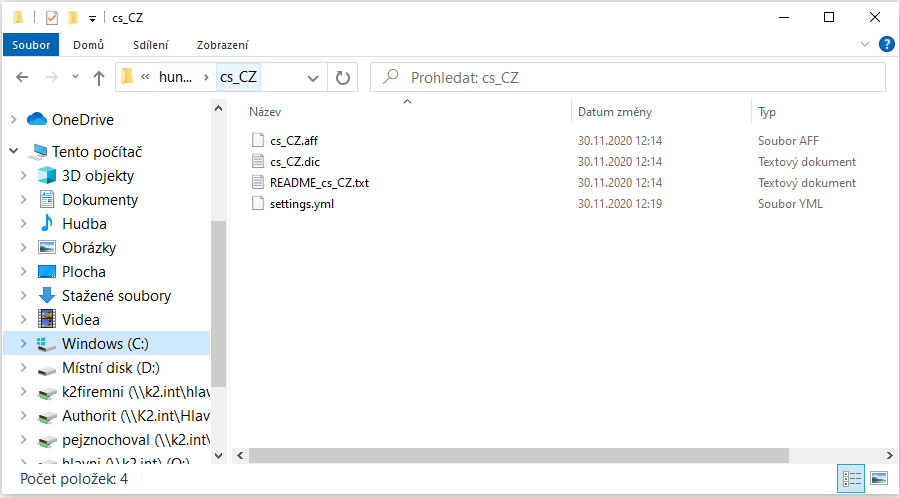
Obr. Příklad výsledné souborové struktury
Po doplnění všech slovníků je nutné restartovat službu Elasticsearch.
Instalace dalších nástrojů
Pro možnost správy, ladění hledacích dotazů a vyhodnocení je možné nainstalovat další nástroje.
Kibana: https://www.elastic.co/downloads/kibana (nástroj pro testování hledacích dotazů a vyhodnocování).
Cerebero: https://github.com/lmenezes/cerebro (nástroj pro správce, sledování stavu clusteru, apod.).
|
|
|
Konfigurace v K2
Nejprve je nutné provést základní nastavení spojení se službou Elasticsearch. Ve stromovém menu pod uzlem Web a e-shop/Správa a nastavení otevřeme Konfigurace Elasticsearch.
Ve spodní části formuláře se nachází tlačítko Nastavení. Ve formuláři je nutné zadat adresu serveru včetně portu.
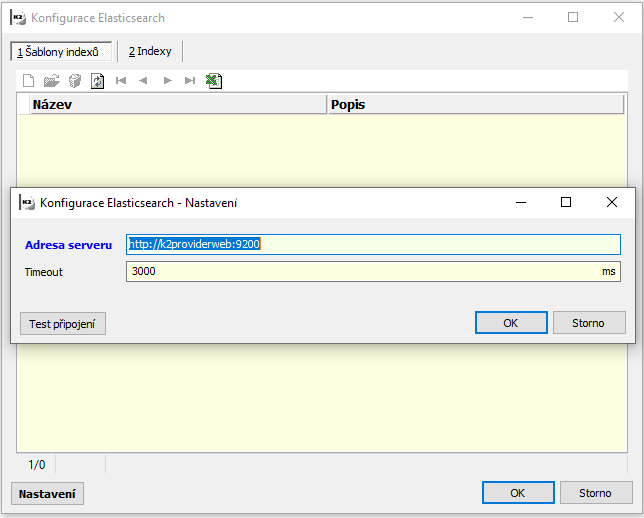
Obr. Konfigurace Elasticsearch
Tlačítkem Test připojení můžeme ověřit, zda K2 dokáže komunikovat s Elasticsearch. V korektním stavu se zobrazí základní stavové informace. V případě chybového stavu se zobrazí podrobnosti o chybě.
|
|
|
Šablony indexů
V dialogu Konfigurace Elasticsearch dále musíme založit Šablony indexů. Každá šablona definuje použité analyzátory textu, včetně souvisejících tokenizerů a filtrů.
Popis těchto prvků je nad rámec dokumentace K2, podrobné informace lze nalézt v dokumentaci Elasticsearch API.
Pro použití Elasticsearch v K2 e-shopu je nutné nadefinovat šablonu indexu pro každý použitý jazyk webu. Šablony musí být pojmenovány shodně a lišit se v koncové části obsahující označení jazyka.
Například:
web_search_cs
web_search_en
web_search_sk
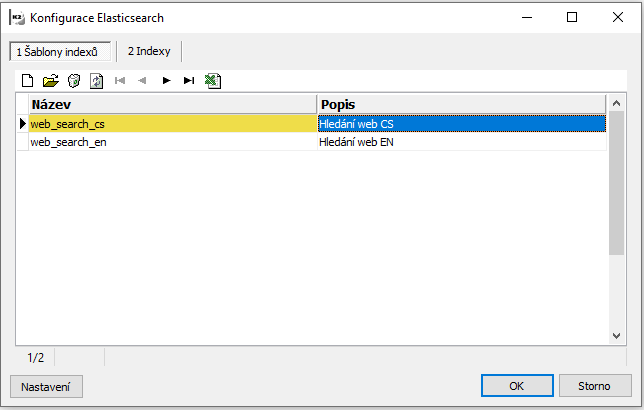
Obr. Konfigurace Elasticsearch - šablony indexů
Příklad vzorové šablony indexu pro češtinu
{
"settings" : {
"index" : {
"number_of_shards" : "1",
"analysis" : {
"filter" : {
"word_delimiter_filter" : {
"preserve_original" : "true",
"catenate_words" : "true",
"generate_number_parts" : "true",
"split_on_case_change" : "false",
"type" : "word_delimiter",
"type_table" : [
"/ => DIGIT",
". => DIGIT",
", => DIGIT",
"- => ALPHANUM"
],
"catenate_numbers" : "true",
"stem_english_possessive" : "false"
},
"czech_hunspell" : {
"locale" : "cs_CZ",
"type" : "hunspell",
"dedup" : "true"
},
"lowercase" : {
"type" : "lowercase"
},
"min_length" : {
"type" : "length",
"min" : "2"
},
"czech_stopwords" : {
"ignore_case" : "true",
"type" : "stop",
"stopwords" : [
"že",
"právě",
"_czech_"
]
},
"unique" : {
"type" : "unique",
"only_on_same_position" : "false"
}
},
"analyzer" : {
"words" : {
"filter" : [
"word_delimiter_filter",
"lowercase",
"icu_folding",
"unique"
],
"tokenizer" : "keyword"
},
"autocomplete" : {
"filter" : [
"lowercase",
"icu_folding"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "autocomplete"
},
"autocomplete_search" : {
"filter" : [
"icu_folding"
],
"tokenizer" : "lowercase"
},
"hunspell" : {
"filter" : [
"min_length",
"lowercase",
"czech_hunspell",
"czech_stopwords",
"icu_folding",
"unique"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "standard"
}
},
"tokenizer" : {
"autocomplete" : {
"token_chars" : [
"letter",
"digit"
],
"min_gram" : "2",
"type" : "edge_ngram",
"max_gram" : "10"
}
}
},
"number_of_replicas" : "1"
}
}
}
Příklad vzorové šablony indexu pro slovenštinu
{
"settings" : {
"index" : {
"number_of_shards" : "1",
"analysis" : {
"filter" : {
"word_delimiter_filter" : {
"preserve_original" : "true",
"catenate_words" : "true",
"generate_number_parts" : "true",
"split_on_case_change" : "false",
"type" : "word_delimiter",
"type_table" : [
"/ => DIGIT",
". => DIGIT",
", => DIGIT",
"- => ALPHANUM"
],
"catenate_numbers" : "true",
"stem_english_possessive" : "false"
},
"slovak_hunspell" : {
"locale" : "sk_SK",
"type" : "hunspell",
"dedup" : "true"
},
"lowercase" : {
"type" : "lowercase"
},
"min_length" : {
"type" : "length",
"min" : "2"
},
"slovak_stopwords" : {
"ignore_case" : "true",
"type" : "stop",
"stopwords" : [
"_slovak_"
]
},
"unique" : {
"type" : "unique",
"only_on_same_position" : "false"
}
},
"analyzer" : {
"words" : {
"filter" : [
"word_delimiter_filter",
"lowercase",
"icu_folding",
"unique"
],
"tokenizer" : "keyword"
},
"autocomplete" : {
"filter" : [
"lowercase",
"icu_folding"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "autocomplete"
},
"autocomplete_search" : {
"filter" : [
"icu_folding"
],
"tokenizer" : "lowercase"
},
"hunspell" : {
"filter" : [
"min_length",
"lowercase",
"slovak_hunspell",
"slovak_stopwords",
"icu_folding",
"unique"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "standard"
}
},
"tokenizer" : {
"autocomplete" : {
"token_chars" : [
"letter",
"digit"
],
"min_gram" : "2",
"type" : "edge_ngram",
"max_gram" : "10"
}
}
},
"number_of_replicas" : "1"
}
}
}
Příklad vzorové šablony indexu pro angličtinu (en_GB)
{
"settings" : {
"index" : {
"number_of_shards" : "1",
"analysis" : {
"filter" : {
"word_delimiter_filter" : {
"preserve_original" : "true",
"catenate_words" : "true",
"generate_number_parts" : "true",
"split_on_case_change" : "false",
"type" : "word_delimiter",
"type_table" : [
"/ => DIGIT",
". => DIGIT",
", => DIGIT",
"- => ALPHANUM"
],
"catenate_numbers" : "true",
"stem_english_possessive" : "false"
},
"english_hunspell" : {
"locale" : "en_GB",
"type" : "hunspell",
"dedup" : "true"
},
"lowercase" : {
"type" : "lowercase"
},
"min_length" : {
"type" : "length",
"min" : "2"
},
"english_stopwords" : {
"ignore_case" : "true",
"type" : "stop",
"stopwords" : [
"_english_"
]
},
"unique" : {
"type" : "unique",
"only_on_same_position" : "false"
}
},
"analyzer" : {
"words" : {
"filter" : [
"word_delimiter_filter",
"lowercase",
"icu_folding",
"unique"
],
"tokenizer" : "keyword"
},
"autocomplete" : {
"filter" : [
"lowercase",
"icu_folding"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "autocomplete"
},
"autocomplete_search" : {
"filter" : [
"icu_folding"
],
"tokenizer" : "lowercase"
},
"hunspell" : {
"filter" : [
"min_length",
"lowercase",
"english_hunspell",
"english_stopwords",
"icu_folding",
"unique"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "standard"
}
},
"tokenizer" : {
"autocomplete" : {
"token_chars" : [
"letter",
"digit"
],
"min_gram" : "2",
"type" : "edge_ngram",
"max_gram" : "10"
}
}
},
"number_of_replicas" : "1"
}
}
}
|
|
|
Nastavení e-shopu v systému K2
Dalším krokem je nastavení konkrétního e-shopu, aby používal vyhledávání přes Elasticsearch.
V knize Weby a e-shopy se do změny uvede daný záznam. Tlačítkem Nastavení webu a e-shopu se otevře konfigurace a na záložku Vyhledávání se zatrhne volba Použít Smart Search vyhledávání.
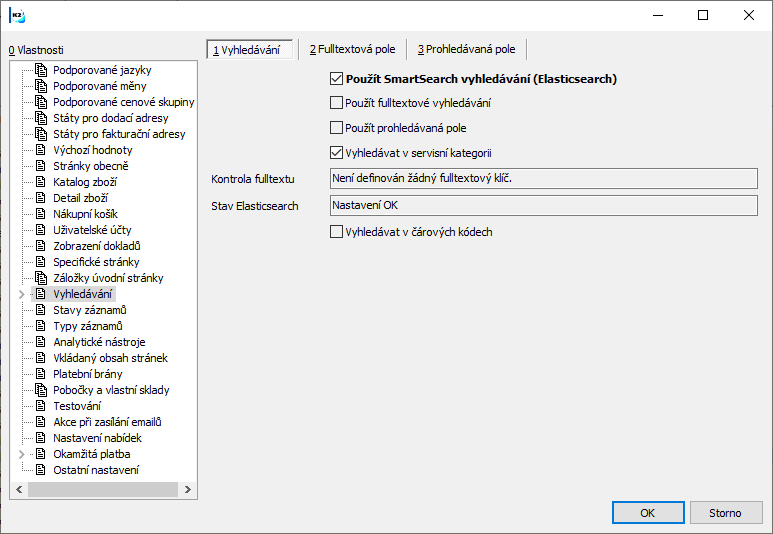
Obr.Použít Smart Search vyhledáváni
Část Nastavení Smart Search nabízí možnost zatrhnout volbu, ve které je požadováno, aby našeptávač vyhledával na e-shopu v plné stránce s výsledky hledání.
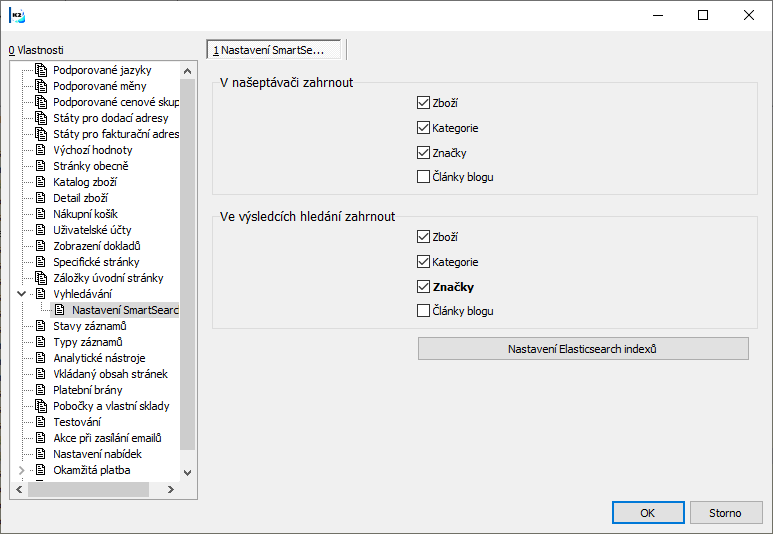
Obr.Nastavení Elasticsearch indexů
Pomocí tlačítka Nastavení indexů se otevře konfigurace Elasticsearch indexů.
Tlačítkem Výchozí nastavení indexů se vygeneruje základní konfigurace a následně se doplní požadované údaje:
- Základní název indexů – pro pojmenování v databázi Elasticsearch. Vzhledem k možnosti provozovat vůči jedné instalaci Elasticsearch více e-shopů i z více různých instalací K2, je vhodné zvolit jednoznačný název, např. dle e-shopu.
- Název šablony indexů – pojmenování šablony indexů vytvořené v předchozím kroku. Pokud je např. šablona pojmenovaná jako web_search_cs, do tohoto pole uvedeme pouze web_search.
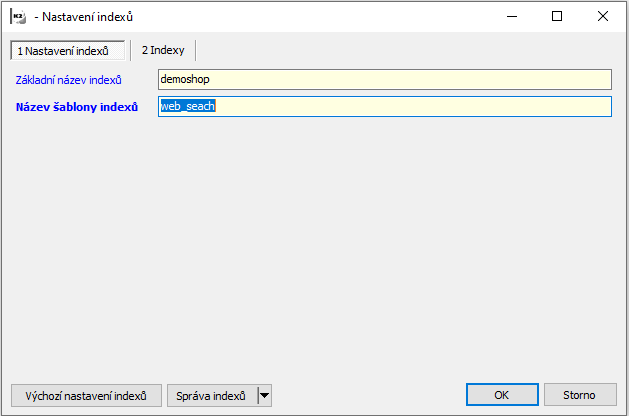
Obr. Nastavení indexů
Poznámka:
Záložka Indexy slouží k detailní konfiguraci indexů pro jednotlivé oblasti hledání (zboží, kategorie atd.) a jednotlivé jazyky. Pro každý index lze nastavit která pole mají být z K2 exportována a jak se má sestavovat hledací dotaz. Hledacím dotazem lze přímo ovlivňovat získané výsledky na webu, lze ovlivňovat prioritu jednotlivých analyzátorů a polí (název, popis, …). Podrobný popis možnosti tvorby hledacích dotazů je nad rámec této dokumentace. Podrobně je popsáno v dokumentaci Elasticsearch.
Ve správě indexů lze zvolit možnost Vytvoření všech indexů. Tímto dojde k vytvoření všech potřebných indexů v Elasticsearch. Vytvoření každého indexu je potvrzeno oknem s odpovědí z Elasticsearch. V případě úspěšného vytvoření indexu je zobrazeno pouze okno s touto informací:
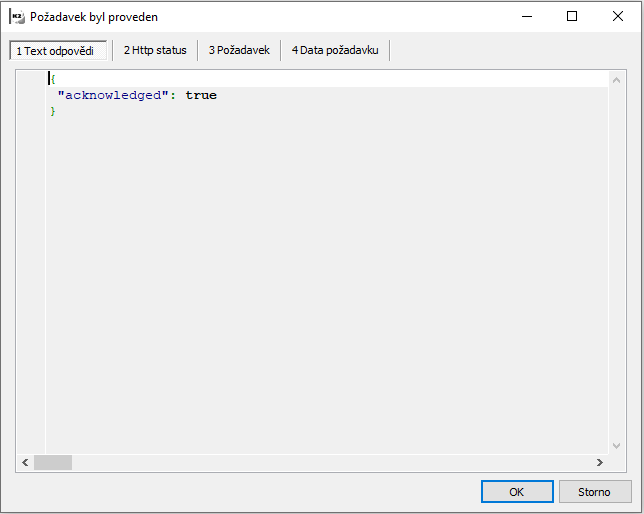
Obr. Úspěšné vytvoření indexu
Nakonec všechny dialogy potvrdíme a uložíme záznam v knize Weby a e-shopy.
V nastavení indexů na záložce indexy je možnost nastavení volitelných parametrů pro jednotlivé segmenty výsledků hledání.
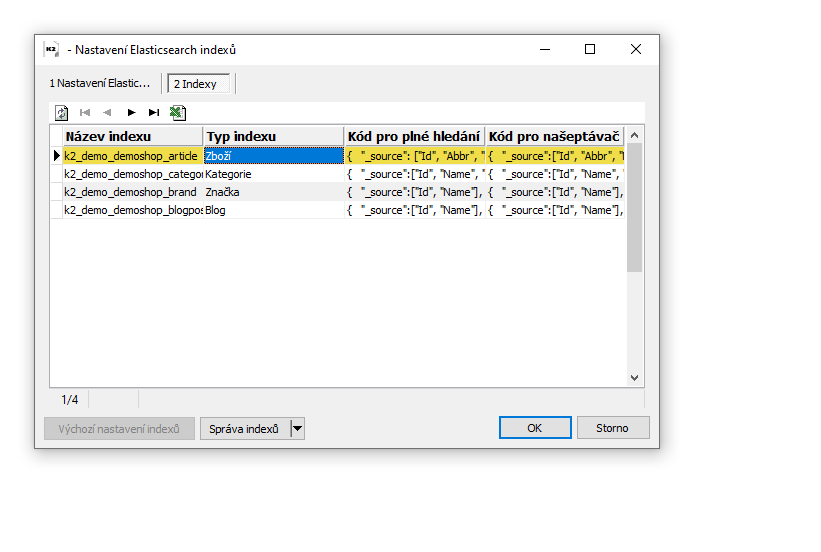
Obr. Nastavení indexů
Například při zvoleném typu indexu Zboží si správce zvolí pomocí zatržítka, které synchronizace se mají v rámci aktualizace na daném segmentu propisovat (exportovat).
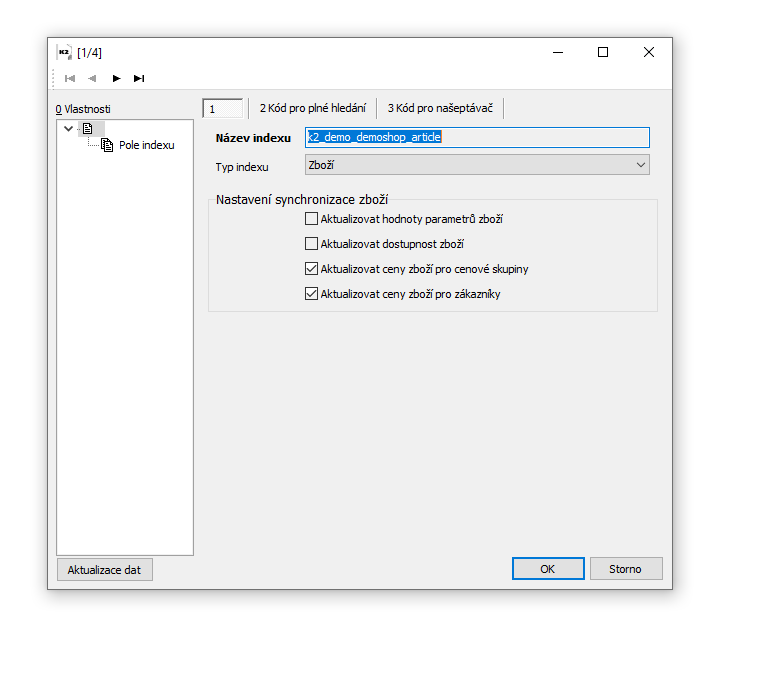
Obr. Typ indexů - synchronizace
|
|
|
Import dat do Elasticsearch
Po základní konfiguraci a vytvoření indexů je nutné vyexportovat data do Elasticsearch. Pro první nahrání dat, případně vynucení ruční aktualizace je možné použít akce, které jsou dostupné v prohlížení nad formulářem s nastavením indexů (viz předchozí kapitola).
K dispozici jsou 2 funkce:
- Kompletní import dat – nahraje z K2 veškerá data (zboží, kategorie, značky, blogové články) do Elasticsearch indexů.
- Aktualizace dat – nahraje do Elasticsearch pouze změněné záznamy od poslední aktualizace nebo kompletního importu dat.
Po spuštění těchto akcí je zobrazen dialog se souhrnem případně výpisem chybových stavů u jednotlivých záznamů.
|
|
|
Automatická aktualizace dat v Elasticsearch
Pro zajištění automatické aktualizace dat v Elasticsearch existuje speciální plánovaná úloha, která zajišťuje inkrementální aktualizace dat v Elasticsearch. Tato plánovaná úloha funguje na principu tzv. časových razítek (polí Timestamp), podle nichž vybírá záznamy změněné od poslední aktualizace a pouze tyto změněné záznamy exportuje z K2.
Plánovaná úloha je k dispozici v nabídce akcí pod názvem Web a e-shop/Elasticsearch: aktualizace dat pro e-shop/web.
Jediným parametrem plánované úlohy je Web/e-shop, jehož data má tato plánovaná úloha aktualizovat.
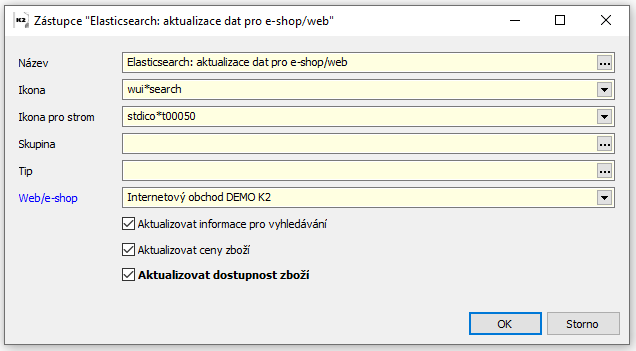
Obr. Zástupce "Elasticsearch: aktualizace dat pro e-shop/web"
|
|
|
Nastavení K2 e-shopu pro použití Elasticsearch
Pro použití Elasticsearch je nutné nakonfigurovat i na straně K2 E-shopu umístěném na webovém serveru. Samostatná konfigurace je nutná z důvodu doporučeného umístění webu/e-shopu v DMZ, kdy je pravděpodobné, že bude Elasticsearch k dispozici pod jiným názvem/IP adresou než z vnitřního doménového prostředí. V konfiguračním souboru config.php je nutno doplnit tyto řádky:
$CONFIG['elasticEnabled'] = true;
$CONFIG['elasticHosts'] = [
[
'host' => 'k2providerweb',
'port' => 9200,
'scheme' => 'http'
]
];
|
|
|
Výsledky hledání a našeptávač na webu
Vzhled našeptávače a výsledků hledání je při použití Smart Search na webu odlišný než v případě klasického vyhledávání.
Do výsledků jsou dle nastavení v K2 zahnuty kromě produktů i kategorie, značky produktů, blogové příspěvky nebo parametry kategorie (např. horská, dětská, atd..)
V našeptávači je vždy zvýrazněn shodující se text.
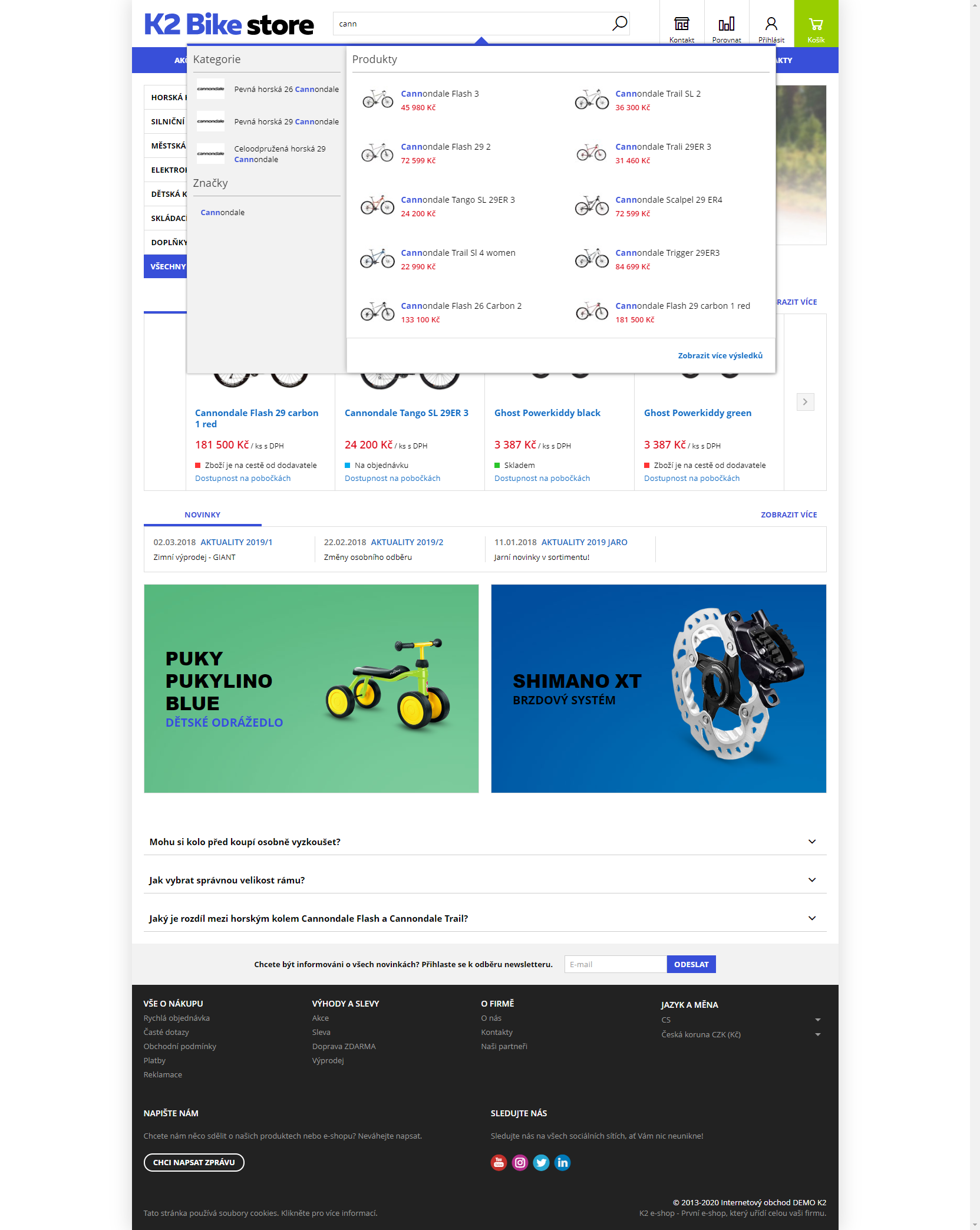
Obr. Našeptávač na webu
Na stránce s výsledky vyhledávání jsou v horní části nejprve uvedeny nalezené značky, následně kategorie a pak teprve konkrétní produkty. Což umožní následné dofiltrování. Nabízí možnost řazení produktů podle vychozí, kódu vzest a sest., názvu vzest. a sest., ceny vzest. a sest. a doporučené.
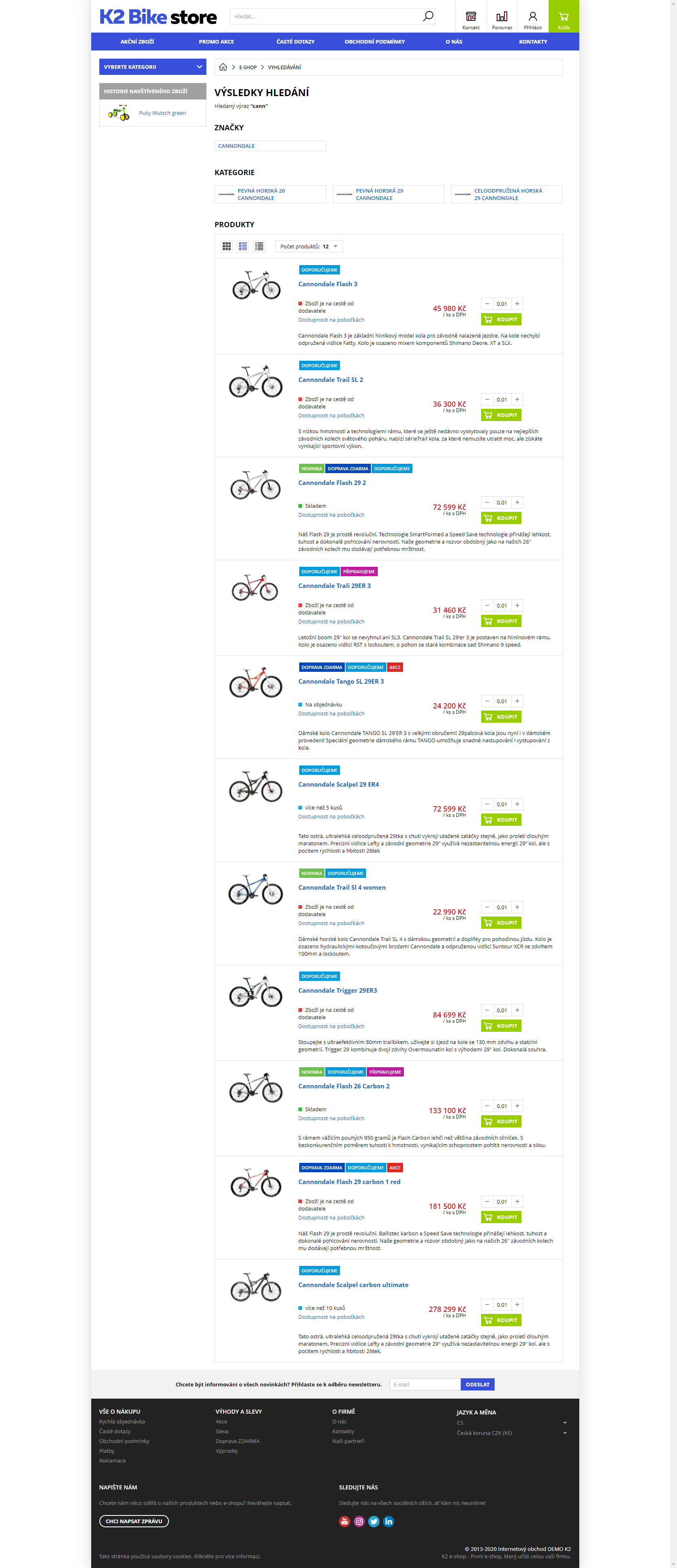
Obr. Výsledky hledání
V případě, že je na hledaný výraz nalezeno velké množství produktů, je uživateli zobrazeno upozornění s přibližným počtem a zobrazeno pouze prvních 500 produktů.
|
|
|
Vyhodnocení funkčnosti vyhledávání
Po nasazení Elasticserach je vhodné po čase vyhodnotit, jak dobře pro konkrétní data konkrétního e-shopu fungují použité analyzátory a použité definice hledacích dotazů. Za účelem vyhodnocení hledaných slov a výrazů je vhodné na webu nasadit Google Analytics. K2 e-shop následně do Google Analytics bude odesílat události pro každé hledání i zobrazení našeptávače. Kromě seznamu nejčastěji hledaných výrazů na webu získáme také seznam výrazů, pro které se nezobrazily žádné výsledky. Pokud se jedná o opakovaný výskyt takových slov, je nutné řešit, proč na tyto výrazy nedostávají uživatelé žádné výsledky. Buď je potřeba hledané fráze dostat do názvů a popisů kategorií a produktů nebo provést optimalizaci nastavení Smart Search.
Informace o hledaných výrazech jsou v Google Analytics k dispozici v sekci Chování/Události. Jedná se o události kategorie search – plné výsledky hledání a searchAutocomplete – výsledky zobrazení našeptávače.
Každá tato kategorie se dále člení:
- Akce – nabývá 2 možných hodnot:
- Results (byl vrácen nějaký výsledek) a
- ZeroResults (na hledaný výraz nebyla zobrazena žádná položka výsledků
- Štítek – obsahuje uživatelem zadaný hledaný výraz
Kromě sledování událostí je také doporučeno nakonfigurovat standardní analýzu vyhledávání v rámci Google Analytics (sekce Chování/Vyhledávání na webu). Tato sekce ale zobrazuje pouze výsledky plného vyhledávání, nezohledňuje průchod přes našeptávač. Pro nastavení plnění dat do této sekce je nutné v konfiguraci webu na stránkách Google Analytics v části Nastavení výběru dat zapnout volbu Sledování vyhledávání webu a doplnit Parametr v URL na hodnotu search.