|
|
|
Elasticsearch K2
|
|
|
Úvod a popis architektury
Nástroj Elasticsearch slouží k rychlému a efektivnímu vyhledávání v rámci e-shopu a IS K2. Nabízí možnost fulltextového vyhledávání včetně skloňování, použití synonym, detekce překlepů a řazení výsledků dle relevance.
Umožňuje vyhledávat také v názvech a popisech kategorií zboží, značek produktů nebo názvech a obsahu blogových článků. Vyhodnocení lze provádět pomocí integrace se službou Google Analytics.
Samotný Elasticsearch je multiplatformní open source produkt, který musí být nainstalován samostatně. IS K2 i K2 e-shop implementují komunikační rozhraní, kterým můžou s Elasticsearch komunikovat.
Pro celkovou funkčnost je nutné zajistit, aby mohla s tímto serverem probíhat komunikace na TCP portu 9200 (výchozí nastavení) jak z vnitřní sítě ze služby K2 Aplikační server, případně terminálového serveru/klientských stanic, na kterých uživatelé provozují IS K2, tak ze strany K2 e-shopu (tedy typicky serveru umístěného v DMZ).
|
|
|
Doporučené produkční nasazení (Linux)
Nasazení na samostatný server na platformě Linux umístěný v DMZ.
Minimální požadavky: 8GB RAM, 2 jádra CPU, 30GB disk.
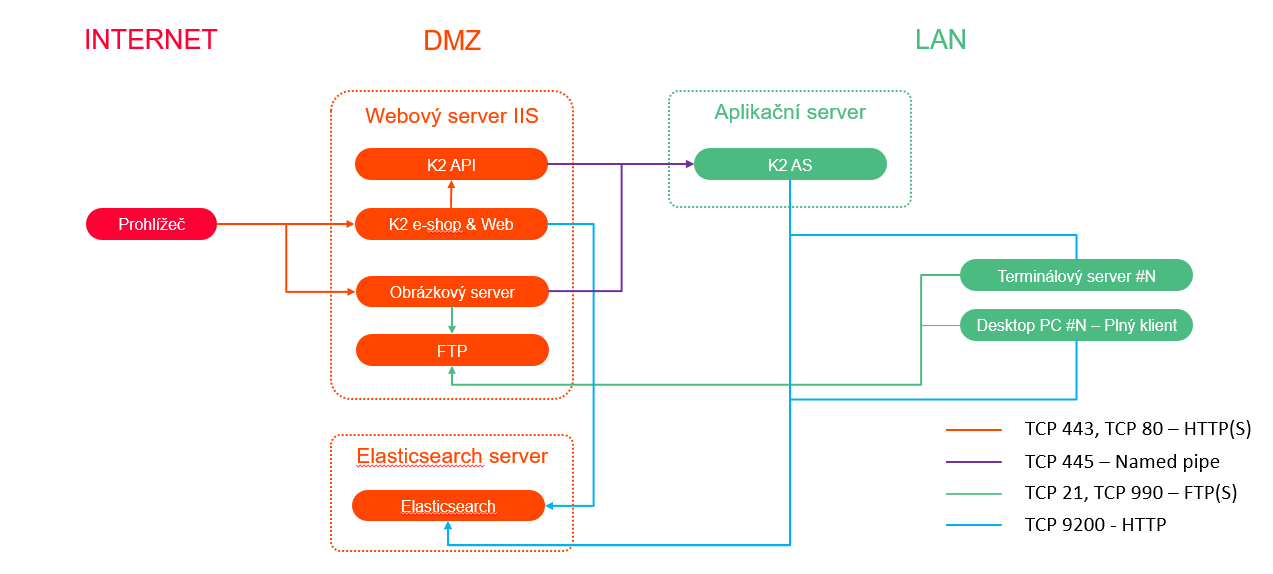
Obr. Doporučené produkční nasazení (Linux)
|
|
|
Nasazení pro testování (Windows)
Varianta pro testovací provoz e-shop. Nepodporováno pro produkční provoz.
Server AS musí mít kromě požadavků ostatních služeb navíc k dispozici alespoň 2GB RAM a dostupnou kapacitu CPU pro provoz Elasticsearch.
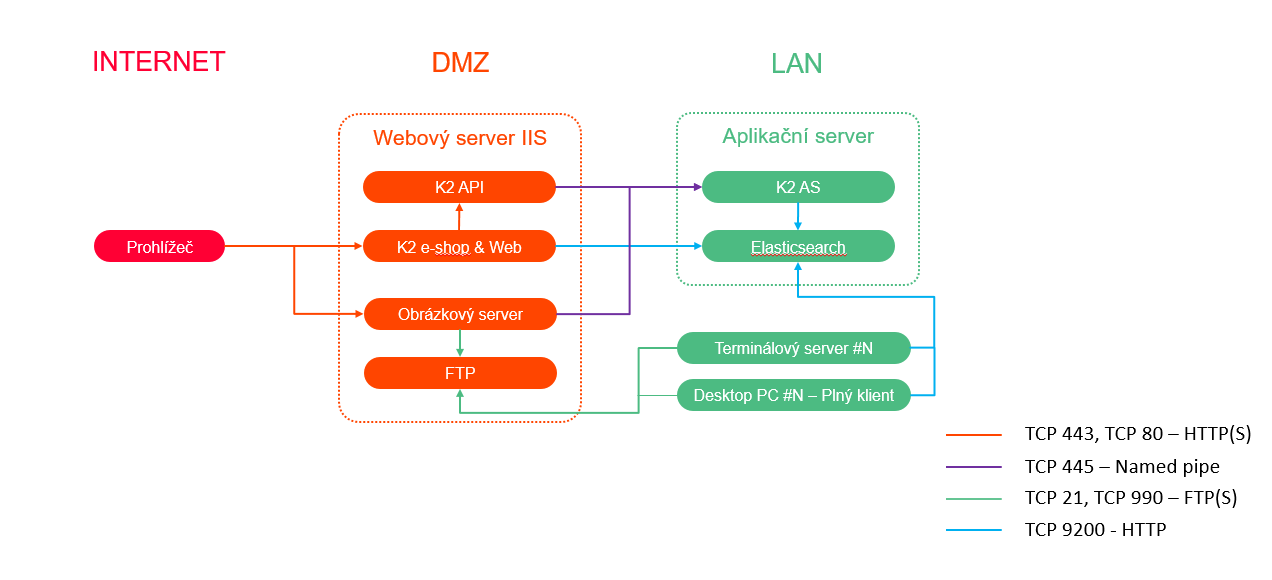
Obr. Nasazení pro testování (Windows)
|
|
|
Instalace Elasticsearch (Linux)
Různé možnosti základní instalace na platformě Linux jsou podrobně popsány na stránkách výrobce Elasticsearch:
https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
Mimo základní instalaci je potřeba instalovat tyto doplňky:
- ICU Analysis plugin: https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-icu.html
- Slovníky pro použité jazyky – viz postup v kapitole „Instalace slovníků pro Elasticsearch„.
|
|
|
Instalace Elasticsearch (Windows)
Různé možnosti základní instalace na platformě Linux jsou podrobně popsány na stránkách výrobce Elasticsearch:
https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
Mimo základní instalaci je potřeba instalovat tyto doplňky:
- ICU Analysis plugin: https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-icu.html
- Slovníky pro použité jazyky – viz postup v kapitole „Instalace slovníků pro Elasticsearch„.
|
|
|
Instalace slovníků pro Elasticsearch
Aby mohla správně fungovat analýza textu a slov pro různé jazyky, je potřeba do Elasticsearch doplnit odpovídající slovníky projektu Hunspell.
Slovníky pro jednotlivé jazyky lze stáhnout například z této stránky: http://download.services.openoffice.org/contrib/dictionaries/
Pro češtinu např. stáhneme soubor cs_CZ.zip. Pro angličtinu en_GB.zip nebo en_US.zip (podle preference britské nebo americké angličtiny).
Stažený ZIP soubor rozbalíme do adresáře s konfiguračními soubory Elasticsearch, tj. adresář zadaný v prvním kroku instalace (zde podle defaultního nastavení Msi instalátoru). Ve výchozím stavu je to C:\ProgramData\Elastic\Elasticsearch\config. Případně /etc/elasticsearch na platformě linux nebo podadresář config v místě rozbalení archivu s Elasticsearch.V tomto adresáři vytvoříme podadresář hunspell a v něm podadresář dle označení jazyka (např. „cs_CZ“). Do vytvořeného adresáře rozbalíme obsah staženého archivu (minimálně soubory s příponou .aff a .dic).
Dále vytvoříme soubor settings.yml, který bude obsahovat tento řádek:
strict_affix_parsing: true
Takto postupujeme pro všechny jazyky, v nichž potřebujeme na e-shopu vyhledávat.
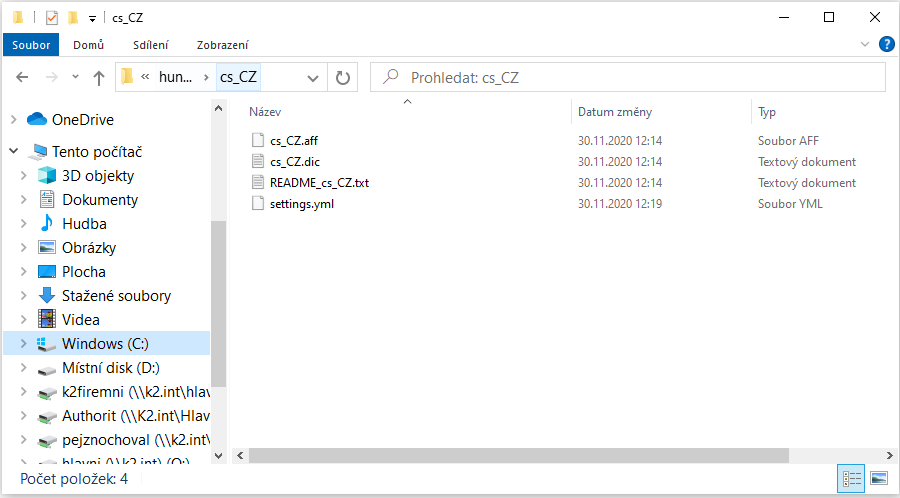
Obr. Příklad výsledné souborové struktury
Po doplnění všech slovníků je nutné restartovat službu Elasticsearch.
|
|
|
Instalace dalších nástrojů
Pro možnost správy, ladění hledacích dotazů a vyhodnocení je možné nainstalovat další nástroje.
Kibana: https://www.elastic.co/downloads/kibana (nástroj pro testování hledacích dotazů a vyhodnocování).
Cerebero: https://github.com/lmenezes/cerebro (nástroj pro správce, sledování stavu clusteru, apod.).
|
|
|
Konfigurace v K2
Nejprve je nutné provést základní nastavení spojení se službou Elasticsearch. V IS K2 je nutné přes pravé tlačítko myši přidat do Oblíbených z části Ostatní funkci Konfigurace Elasticsearch a Elasticsearch indexy.
Pravým tlačítkem myši, nebo klávesou INS přidáme do fomuláře Konfigurace Elasticsearch Uzly Elasticsearch. Zde zadáme adresu serveru vč. portu, přihlašovací údaje a zvolíme zatržítko, zda chceme Elasticsearch využít pro E-shop, nebo pro K2.
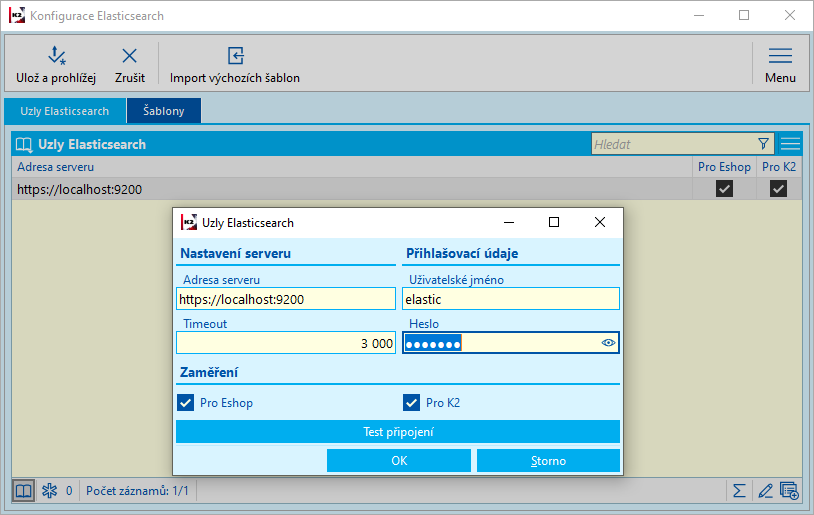
Obr. Konfigurace Elasticsearch
Tlačítkem Test připojení můžeme ověřit, zda K2 dokáže komunikovat s Elasticsearch serverem. V korektním stavu se zobrazí základní stavové informace. V případě chybového stavu se zobrazí podrobnosti o chybě.
Tlačítkem Import výchozích šablon se nám naimportují výchozí šablony pro Elasticsearch. Tyto šablony lze zobrazit na záložce šablony a lze je zde také upravovat. Šablony indexů jsou popsány zde.
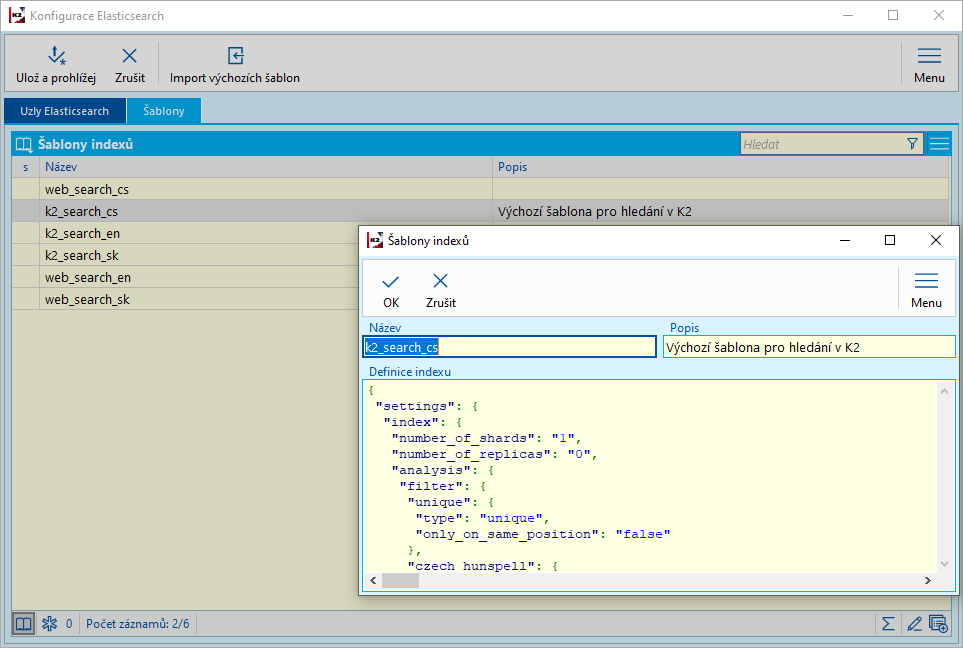
Obr.: Import výchozích šablon
|
|
|
Funkce Elasticsearch pro IS K2
Ve funkci Elasticsearch indexy definujeme data pro Elasticsearch vyhledávání pomocí klávesy INS, nebo pravým tlačítkem myši Záznam - Nová položka.
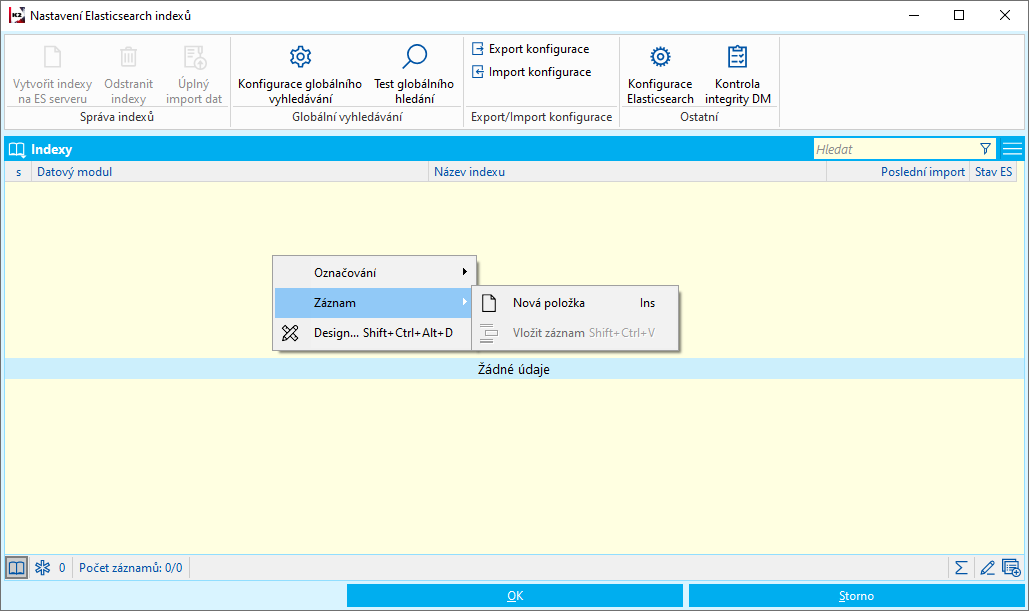
Obr.: Nový záznam Elasticsearch indexů
Popis polí:
Vytvořit indexy na ES serveru |
Provede vytvoření nadefinovaných indexů na Elasticsearch serveru. |
Odstranit indexy |
Provede odstranění všech označených indexů, nebo indexu, na kterém stojí pravítkovybraný z Elasticsearch serveru vč. odstranění definice indexu z IS K2. |
Úplný import dat |
Na označených záznamech, nebo na záznamu, na kterém stojí pravítko dojde k výmazu a vytvoření dat na Elasticsearch serveru. |
Konfigurace globálního vyhledávání |
Zde je nastavena výchozí konfigurace pro globální vyhledávání. Jedná se o obecnou konfiguraci globálního vyhledávání. |
Test globálního vyhledávání |
Zde je možné vyzkoušet, zda bude fungovat globální vyhledávání na webové K2. |
Export konfigurace |
Pomocí této funkce lze vyexportovat nastavení Elasticsearch indexů. |
Import konfigurace |
Provede import konfigurace Elasticsearch indexů z vybraného souboru. |
Konfigurace Elasticsearch |
Blíže je popsáno zde. |
Kontrola integrity DM |
Toto tlačítko se použije po reinstalaci IS K2, aby se provedla kontrola, zda se nezměnila struktura datového modulu. |
|
|
|
Elasticsearch indexy
Do pole Indexy vložíme všechny datové moduly, pro které chceme nastavit vyhledávání.
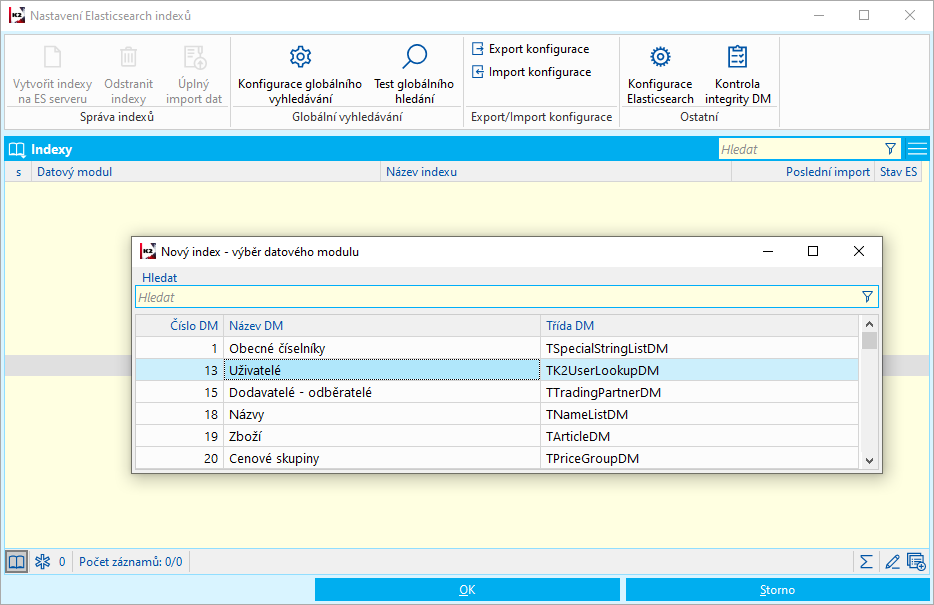
Obr.: Definice vybraného indexu
U nového indexu se nastaví Identifikátor pro rozlišení indexu na Elasticsearch serveru.
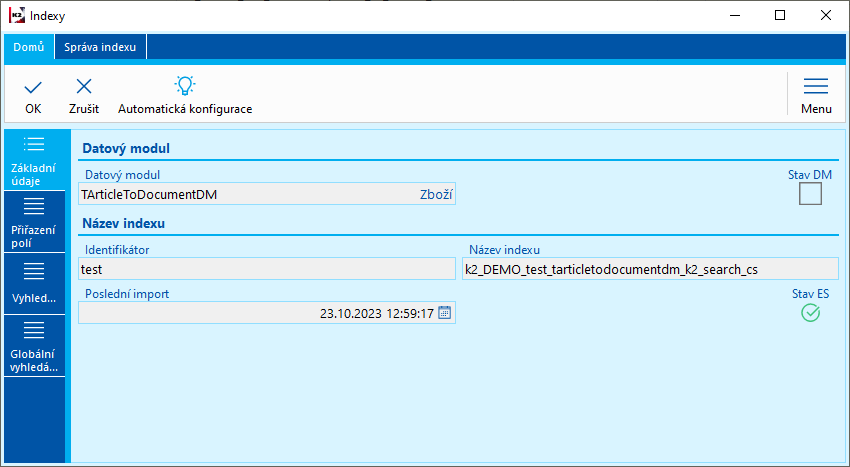
Obr.: Nový index
Popis polí:
Datový modul |
Identifikace datového modulu. |
|
Identifikátor |
Slouží pro rozlišení celé skupiny indexů. |
|
Název indexu |
Název indexu se vytvoří automaticky a skládá se z prefixu. |
|
Poslední import |
Datum a čas, kdy byl proveden poslední import indexu na Elasticsearch server. |
|
Stav ES |
Informace, zda index existuje na Elasticsearch serveru. Můžou se zobrazit tyto stavy indexu: |
|
|
|
index neexistuje na serveru |
|
|
index existuje na serveru |
|
|
index nelze ověřit (může být chyba na serveru) |
Další záložkou je Přiřazení polí. Zde vybíráme pole, ve kterých se bude provádět elasticsearch vyhledávání. Pole si můžeme nadefinovat, nebo využít přednastavení:
- Výchozí pole pro našeptávač - přiřadí výchozí pole, která jsou zadána ve výchozí šabloně pro Elasticsearch. Jedná se o pole uvedena v lokátoru daného datového modulu. V těchto polích bude probíhat vyhledávání prostřednictvím Elasticsearch.
- Výchozí pole pro globální vyhledávání - nastaví se pole, která se použijí pro globální vyhledávání ve webové K2.
Na záložce Vyhledávání definujeme dotazy pro vyhledávání Elasticsearch. Pro výchozí vyhledávání je nastaven našeptávač. Jsou zde uvedena pole, ve kterých bude probíhat vyhledávání, omezení počtu záznamů,.. Pro jednotlivá pole lze nastavit také toleranci hledání nepřesnosti, zadat délku prefixu pole, nebo jeho prioritu. Po zapnutí Expert režimu lze dotazy upravovat. Expertní režim se nedoporučuje používat, pokud se uživatel opravdu neorientuje v Elasticsearch.
Na záložce Globální vyhledávání je zatržítko Povoleno pro GS. Tímto zatržítkem určujeme, zda má globální vyhledávání probíhat na webové K2. Pokud je odtrženo, bude Elasticsearch vyhledávání probíhat pouze nad indexy,které jej mají zatrženo.
Na záložce Správa indexu je možné využít tyto funkce:
- Odstranění ES indexu - odstraní daný index z Elasticsearch serveru, ale zachová jeho definici.
- Synchronizovat data - reflektuje pouze změny provedené v IS K2 od posledního importu.
- Existence na ES serveru - ověří, zda index existuje na Elasticsearch serveru.
- Test analyzátoru - zde je možné vyzkoušet, jak daný analyzátor zpracovává požadované slovo, znak, číslo,..
Po nastavení Elasticsearch indexů a jejich navedení na Elasticsearch server, je možné v IS K2 využít Elasticsearch podmínku ve filtru a použít dané vyhledávání také ve webové K2.
Pro synchronizaci dat lze v Plánovači úloh využít Položku dávky - Elasticsearch - synchronizace dat. Díky tomuto nastavení se bude v plánovaném čase spouštět automatická synchronizace dat na Elasticsearch server. Tato úloha doplňuje změny v datech od posledního importu. Úplný import dat lze provést pouze ve funkci Elasticsearch indexy, která je pospána výše. Úlohu lze nastavit pro jeden index, nebo pro všechny najednou. Toto se hodí v případě, že některé datové indexy se mění častěji než jiné.
|
|
|
Nastavení SQL serveru pro použití Elasticsearch
Pro propojení SQL serveru a Elasticsearch je zapotřebí využít funkci 798 - Nastavení SQL serveru pro použití elasticsearch.
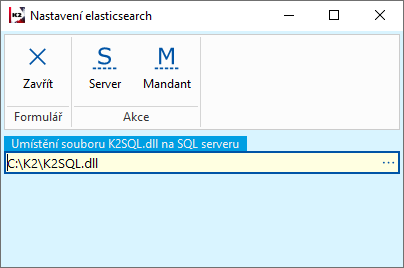
Obr.: Nastavení SQL serveru pro použití elasticsearch
V části Umístění souboru K2SQL.dll na SQL serveru vybíráme cestu k danému souboru. Tento soubor musí být umístěn ve složce, která je viditelná pro SQL server.
Pro konfiguraci s SQL serverem je třeba využít tlačítko Server a poté se využije tlačítko Mandant, pro navedení na konkrétního mandanta.
|
|
|
Funkce Smart Search (e-shop)
Funkce Smart Search slouží k rychlému a efektivnímu vyhledávání v rámci e-shopu.
Bližší popis k funkci Smart Search (eshop) najdete zde.
|
|
|
Šablony indexů
V dialogu Konfigurace Elasticsearch dále musíme založit Šablony indexů. Každá šablona definuje použité analyzátory textu, včetně souvisejících tokenizerů a filtrů.
Popis těchto prvků je nad rámec dokumentace K2, podrobné informace lze nalézt v dokumentaci Elasticsearch API.
Pro použití Elasticsearch v K2 e-shopu je nutné nadefinovat šablonu indexu pro každý použitý jazyk webu. Šablony musí být pojmenovány shodně a lišit se v koncové části obsahující označení jazyka.
Například:
web_search_cs
web_search_en
web_search_sk
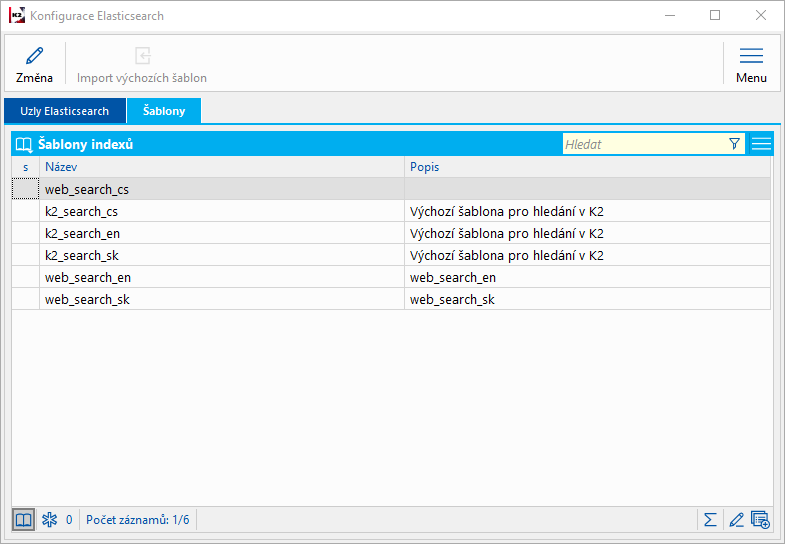
Obr. Konfigurace Elasticsearch - šablony indexů
|
|
|
Příklad vzorové šablony indexu pro češtinu
{
"settings" : {
"index" : {
"number_of_shards" : "1",
"analysis" : {
"filter" : {
"word_delimiter_filter" : {
"preserve_original" : "true",
"catenate_words" : "true",
"generate_number_parts" : "true",
"split_on_case_change" : "false",
"type" : "word_delimiter",
"type_table" : [
"/ => DIGIT",
". => DIGIT",
", => DIGIT",
"- => ALPHANUM"
],
"catenate_numbers" : "true",
"stem_english_possessive" : "false"
},
"czech_hunspell" : {
"locale" : "cs_CZ",
"type" : "hunspell",
"dedup" : "true"
},
"lowercase" : {
"type" : "lowercase"
},
"min_length" : {
"type" : "length",
"min" : "2"
},
"czech_stopwords" : {
"ignore_case" : "true",
"type" : "stop",
"stopwords" : [
"že",
"právě",
"_czech_"
]
},
"unique" : {
"type" : "unique",
"only_on_same_position" : "false"
}
},
"analyzer" : {
"words" : {
"filter" : [
"word_delimiter_filter",
"lowercase",
"icu_folding",
"unique"
],
"tokenizer" : "keyword"
},
"autocomplete" : {
"filter" : [
"lowercase",
"icu_folding"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "autocomplete"
},
"autocomplete_search" : {
"filter" : [
"icu_folding"
],
"tokenizer" : "lowercase"
},
"hunspell" : {
"filter" : [
"min_length",
"lowercase",
"czech_hunspell",
"czech_stopwords",
"icu_folding",
"unique"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "standard"
}
},
"tokenizer" : {
"autocomplete" : {
"token_chars" : [
"letter",
"digit"
],
"min_gram" : "2",
"type" : "edge_ngram",
"max_gram" : "10"
}
}
},
"number_of_replicas" : "1"
}
}
}
|
|
|
Příklad vzorové šablony pro slovenštinu
{
"settings" : {
"index" : {
"number_of_shards" : "1",
"analysis" : {
"filter" : {
"word_delimiter_filter" : {
"preserve_original" : "true",
"catenate_words" : "true",
"generate_number_parts" : "true",
"split_on_case_change" : "false",
"type" : "word_delimiter",
"type_table" : [
"/ => DIGIT",
". => DIGIT",
", => DIGIT",
"- => ALPHANUM"
],
"catenate_numbers" : "true",
"stem_english_possessive" : "false"
},
"slovak_hunspell" : {
"locale" : "sk_SK",
"type" : "hunspell",
"dedup" : "true"
},
"lowercase" : {
"type" : "lowercase"
},
"min_length" : {
"type" : "length",
"min" : "2"
},
"slovak_stopwords" : {
"ignore_case" : "true",
"type" : "stop",
"stopwords" : [
"_slovak_"
]
},
"unique" : {
"type" : "unique",
"only_on_same_position" : "false"
}
},
"analyzer" : {
"words" : {
"filter" : [
"word_delimiter_filter",
"lowercase",
"icu_folding",
"unique"
],
"tokenizer" : "keyword"
},
"autocomplete" : {
"filter" : [
"lowercase",
"icu_folding"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "autocomplete"
},
"autocomplete_search" : {
"filter" : [
"icu_folding"
],
"tokenizer" : "lowercase"
},
"hunspell" : {
"filter" : [
"min_length",
"lowercase",
"slovak_hunspell",
"slovak_stopwords",
"icu_folding",
"unique"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "standard"
}
},
"tokenizer" : {
"autocomplete" : {
"token_chars" : [
"letter",
"digit"
],
"min_gram" : "2",
"type" : "edge_ngram",
"max_gram" : "10"
}
}
},
"number_of_replicas" : "1"
}
}
}
v
|
|
|
Příklad vzorové šablony indexu pro angličtinu (en_GB)
{
"settings" : {
"index" : {
"number_of_shards" : "1",
"analysis" : {
"filter" : {
"word_delimiter_filter" : {
"preserve_original" : "true",
"catenate_words" : "true",
"generate_number_parts" : "true",
"split_on_case_change" : "false",
"type" : "word_delimiter",
"type_table" : [
"/ => DIGIT",
". => DIGIT",
", => DIGIT",
"- => ALPHANUM"
],
"catenate_numbers" : "true",
"stem_english_possessive" : "false"
},
"slovak_hunspell" : {
"locale" : "sk_SK",
"type" : "hunspell",
"dedup" : "true"
},
"lowercase" : {
"type" : "lowercase"
},
"min_length" : {
"type" : "length",
"min" : "2"
},
"slovak_stopwords" : {
"ignore_case" : "true",
"type" : "stop",
"stopwords" : [
"_slovak_"
]
},
"unique" : {
"type" : "unique",
"only_on_same_position" : "false"
}
},
"analyzer" : {
"words" : {
"filter" : [
"word_delimiter_filter",
"lowercase",
"icu_folding",
"unique"
],
"tokenizer" : "keyword"
},
"autocomplete" : {
"filter" : [
"lowercase",
"icu_folding"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "autocomplete"
},
"autocomplete_search" : {
"filter" : [
"icu_folding"
],
"tokenizer" : "lowercase"
},
"hunspell" : {
"filter" : [
"min_length",
"lowercase",
"slovak_hunspell",
"slovak_stopwords",
"icu_folding",
"unique"
],
"char_filter" : [
"html_strip"
],
"type" : "custom",
"tokenizer" : "standard"
}
},
"tokenizer" : {
"autocomplete" : {
"token_chars" : [
"letter",
"digit"
],
"min_gram" : "2",
"type" : "edge_ngram",
"max_gram" : "10"
}
}
},
"number_of_replicas" : "1"
}
}
}